df_price = get_spot_price() / 1000.0 # prices in €/kWh instead of €/GWhoptimal_dispatch
Investigate optimal dispatch techniques
1. Introduction
Electricity is sold on the day-ahead market. Sellers and buyers submit their bids for the coming day before noon on a given day. A seller of electricity sells energy for each hour of the next day and receives a compensation for that based on the day-ahead (spot) price of that given day. If there’s a mismatch between the amount of electricity that the seller sold and what the seller actually delivered, then the seller receives or pays a compensation based on the imbalance price. The seller receives a compensation if the seller produced more energy than what was sold and pays a compensation in case more energy was sold than delivered.
Traditional power plants are controllable (to different degrees) whereas photovoltaïc (and wind) assets are mostly dependent on weather conditions (and therefore uncontrollable). This uncontrollability can bring significant uncertainty to the revenue of these renewable assets.
In case of photovoltaïc plants, there are two main issues contributing to financial risk. First, many European countries now have a significant portion of their total energy production sourced from photovoltaïc assets (>10%). As a result, moments of high photovoltaïc energy production increasingly result in downward pressure on the day-ahead prices due to higher energy supply resulting in lower revenues. Second, renewable energy, unlike traditional power plants, are mostly uncontrollable since energy production is driven by weather conditions. Because of this, estimating the energy to be sold on the day-ahead market has higher risks of large imbalance costs, since production is driven by uncontrollable factors and therefore has to be forecasted.
One solution to potentially reduce the finanical risks from the two before-mentioned issues is to combine photovoltaïc assets with energy storage solutions to have more control on when energy is dispatched to the electricity grid. Energy storage could mitigate the risk of the lower prices on hours of high production by dispatching the energy to the grid on hours with higher prices. Batteries could as well mititage some of the incurred imbalance costs by rebalancing the energy returned to the grid such that the sold energy at each hour more closely matches the actual energy returned to the grid.
In Section 2, we will discuss how batteries could help with dispatching energy to the grid to sell this energy at higher prices. In Section 3, we introduce an extension to the analysis in Section 2 by investigating the higher inherit imbalance risks for photovoltaïc assets.
2. Optimal Energy Dispatching using Battery Storage
Before trying to optimise revenues, let’s start by defining what the revenue is supposed to look like. For any given day, let \(P_t\) be the day-ahead price in €/kWh at hour \(t\) and \(V_t\) the ingested production in kW at time \(t\). The revenue is then defined as:
\[ R = \sum_{t=0}^{23} P_t V_t \]
The main observation here is that we have some control over \(V_t\) so that we can try to ingest energy to the grid at hours with higher prices.
Day-ahead prices
The next figure shows the normalised prices over the last two years together:
df_price_normal = df_price.groupby(pd.Grouper(freq="1d"), group_keys=False).apply(
lambda d: d / d.mean()
)
# create wide for boxplot and remove duplicate date, hour tuples due to change to winter time
df_price_normal = df_price_normal.to_frame().assign(
hour=lambda d: d.index.hour, date=lambda d: d.index.date
)
df_price_normal = df_price_normal[~df_price_normal[["hour", "date"]].duplicated()]
df_price_normal.pivot(index="date", columns="hour", values="spot_price").plot.box()
plt.show()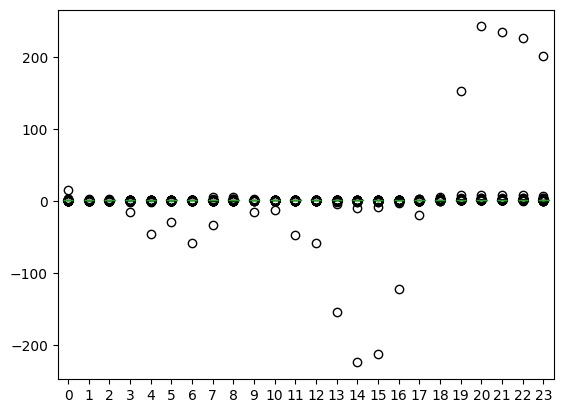
It’s hard to get a good sense of the daily distribution since we have a few hours with extremely large values – 200 means that the price is 200 times higher than the average of that day! However, note that extremely low prices happen around noon whereas the extremely high prices happen during during the evening.
The following boxplot contains the same data without prices that are 10 times higher/lower than the average price
df_price_normal[df_price_normal["spot_price"].abs() < 10].pivot(
index="date", columns="hour", values="spot_price"
).plot.box()
plt.show()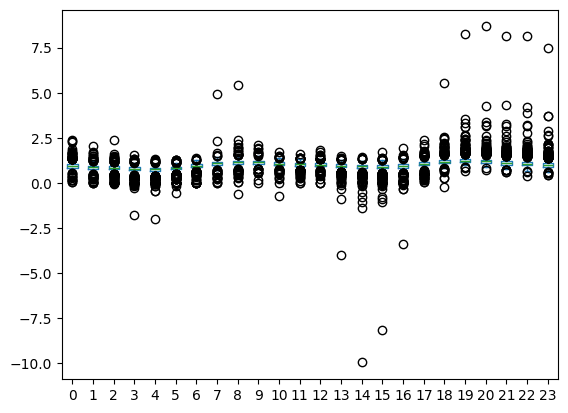
Unsurprisingly, electricity prices are higher at hours of high demand (morning and evening) and lower during off-peak hours (afternoon and night). Another reason for relatively low prices during the afternoon is because photovoltaic plants produce the most during the afternoon.
Peak / Off-peak Spread
Because of the increasing share of photovoltaïc generation, the spread between the prices for peak hours and off-peak hours is increasing over time.
is_peak
is_peak (hour:int)
Returns True if time_stamp is a peak hour, else False.
df_peak_spread = (
df_price.copy()
.to_frame("spot_price")
.assign(peak=lambda d: d.index.hour.map(is_peak))
.groupby(pd.Grouper(freq="1d"))
.apply(
lambda d: d.loc[d["peak"], "spot_price"].mean()
/ d.loc[~d["peak"], "spot_price"].mean()
)
)
df_peak_spread.index = df_peak_spread.index.date
ax = df_peak_spread.plot(title="Peak spread", ylim=(1, 2.0), figsize=(10, 3))
plt.show()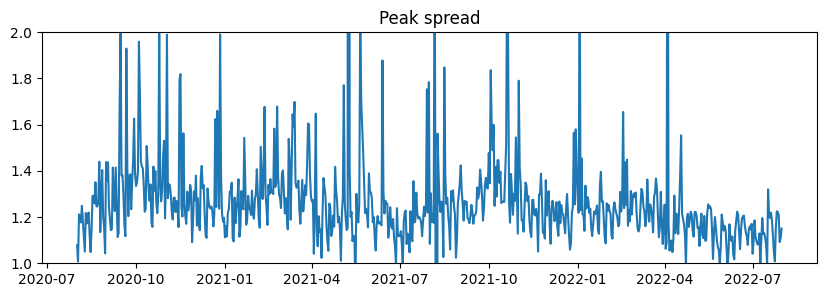
Production
The hourly distribution of our photovoltaic plant looks as follows:
df_prod = get_production()
df_prod_help = df_prod.to_frame("prod").assign(
hour=lambda d: d.index.hour, date=lambda d: d.index.date
)
df_prod_help = df_prod_help.loc[~df_prod_help[["date", "hour"]].duplicated()]
ax = df_prod_help.pivot(index="date", columns="hour", values="prod").plot.box()
plt.show()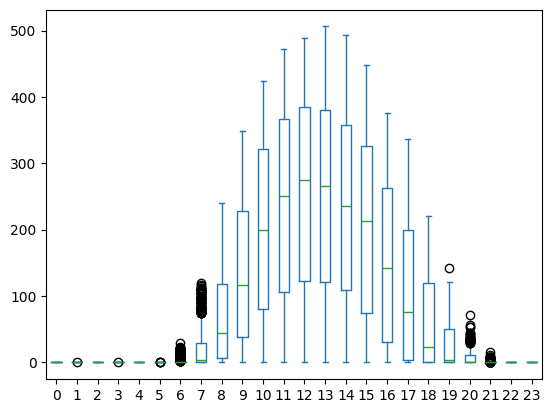
On-peak vs. Local Revenue
To get an indication of the “lost” revenue due to producing energy at hours with low prices (afternoon) we can compare the on-peak revenue with the local revenue. We define the on-peak volume as the local volume but redistributed over the on-peak hours. For this we define a simple helper function to redistribute the volume:
redistribute_daily_production
redistribute_daily_production (df:pandas.core.series.Series, daily_distribution:list[str])
| Type | Details | |
|---|---|---|
| df | Series | production data |
| daily_distribution | list | distribution at each our |
| Returns | DataFrame |
peak_dist = [is_peak(hour) for hour in range(24)]
df_prod_peak = redistribute_daily_production(df_prod, daily_distribution=peak_dist)Local price:
df_revenue_local = (
df_price.to_frame()
.merge(df_prod, left_index=True, right_index=True)
.assign(revenue=lambda d: d["prod"] * d["spot_price"])
)
df_price_local = df_revenue_local.groupby(
pd.Grouper(freq="MS"), group_keys=False
).apply(lambda d: d["revenue"].sum() / d["prod"].sum())Let’s compare the local and the baseload price…
df_price_baseload = df_price.groupby(pd.Grouper(freq="MS"), group_keys=False).mean()df_prices = df_price_baseload.to_frame("baseload").merge(
df_price_local.to_frame("local"), left_index=True, right_index=True
)
ax = df_prices.plot(style="-o", title="Monthly average price (€/kWh)")
plt.show()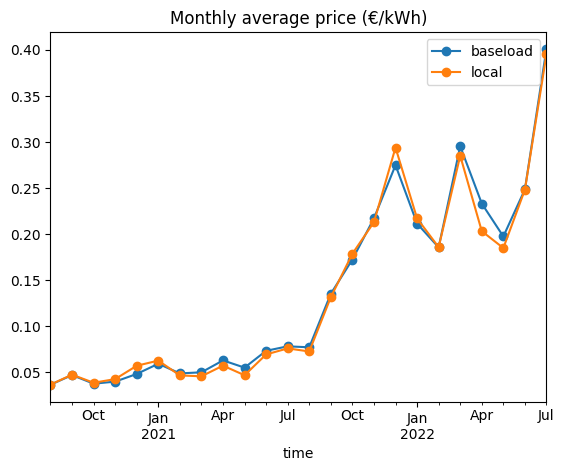
The local price is already significantly lower than the baseload price. Let’s get some first insights in the potential extra revenue from dispatching our local generation on peak hours.
df_revenue_peak = (
df_price.to_frame()
.merge(df_prod_peak, left_index=True, right_index=True)
.assign(revenue=lambda d: d["prod"] * d["spot_price"])
)
df_price_peak = df_revenue_peak.groupby(pd.Grouper(freq="MS"), group_keys=False).apply(
lambda d: d["revenue"].sum() / d["prod"].sum()
)df_prices = df_prices.merge(
df_price_peak.to_frame("peak"), left_index=True, right_index=True
)
ax = df_prices.plot(style="-o", title="Monthly average price (€/kWh)")
plt.show()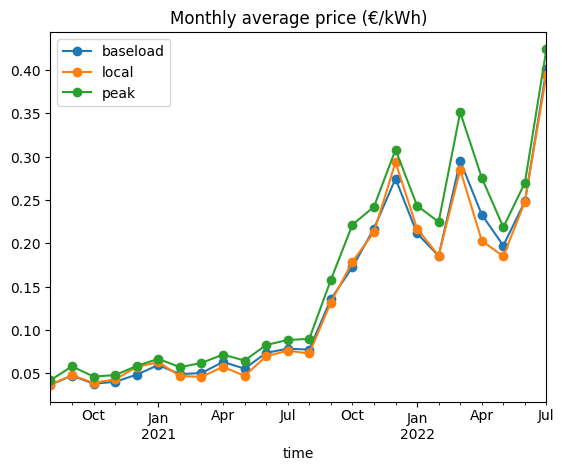
The previous analysis focused on the average monthly price. A more important metric for developers is total revenue over a period.
Since solar plants produce more during summer months, the cannibalisation effect is higher during these months. That implies that the potential revenue benefits of rebalancing production are higher for the production-weighted total revenue over the entire two year period. Let’s crank these numbers…
df_prod_monthly = (
df_prod.groupby(pd.Grouper(freq="MS"), group_keys=False).sum().to_frame("prod")
)df_revenue_comparison = (
df_prices.reset_index()
.melt(id_vars="time", var_name="price_type", value_name="price")
.set_index("time")
.merge(df_prod_monthly, left_index=True, right_index=True)
.assign(revenue=lambda d: d["price"] * d["prod"])
.groupby("price_type")
.sum()[["revenue"]]
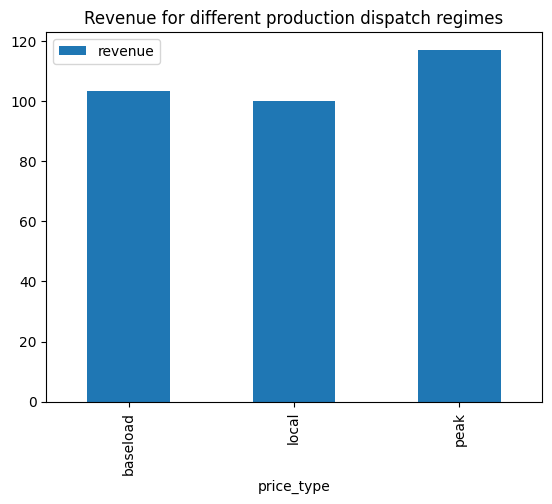
)This results in the following table. It seems that “optimally” rebalancing the production can lead to a ~15% increase in revenue.
ax = (100 * df_revenue_comparison / df_revenue_comparison.T["local"]).plot.bar(
title="Revenue for different production dispatch regimes"
)
plt.show()